Basics Of Consistency And Locking In Databases
Let’s learn about consistency, transaction isolation levels and locking in InnoDB.
ACID
A database transaction is a unit of work performed in a database management system. Such as creating a record, updating a record, deleting a record and so on.
ACID is an acronym that stands for Atomicity, Consistency, Isolation and Durability. These are the four properties of a reliable database transaction.
“C” for Consistency
This blog post focuses on the consistency aspect of database transactions.
Consistency ensures data integrity intact at all times. Meaning, the database will be in a valid state at all times.
Let’s imagine a shopping scenario to understand consistency better. The following may represent the steps to process such action:
- User adds item to cart
- Item quantity checked
- User pays for the item using their online wallet
- Payment approved
- Item quantity updated
- User balance updated
- Order processed
| Item ID | Price | Quantity |
|---|---|---|
| 9 | 200.00 | 1 |
| Wallet ID | Balance |
|---|---|
| 42 | 500.00 |
Imagine these steps are part of a single database transaction. We expect a consistent database to be in this state once the transaction completes:
| Item ID | Price | Quantity |
|---|---|---|
| 9 | 200.00 | 0 |
| Wallet ID | Balance |
|---|---|
| 42 | 300.00 |
This shows that database was never been in an invalid state. If consistency was not guaranteed we could have the database in such state:
| Item ID | Price | Quantity |
|---|---|---|
| 9 | 200.00 | 0 |
| Wallet ID | Balance |
|---|---|
| 42 | 500.00 |
Do you see the problem here? Database processed the order but for some reason the wallet balance is not changed. This is an inconsistent state for the database. And this inconsistency may damage our business.
What happens at different level of Consistency lacks?
Three phenomena explain what might happen in case of a failed consistency guarantee.
In databases “committing” means permanently saving the data in the database.
1. Dirty Reads
Transaction T1 can read a not yet committed data from other transactions.
Imagine the transaction for the above shopping to look like this:
1. BEGIN;
2. “User adds item to cart”
3. “Item quantity checked”
4. “User pays for the item using their online wallet”
5. “Payment approved”
6. “Item quantity updated”
7. “User balance updated”
8. “Order processed”
9. COMMIT;
Now imagine that there’s only one item left in the stock.
- User 1 starts the transaction T1 goes through the steps 1 to 8.
- Right after that User 2 tries to view the details of this item.
Even though transaction T1 is not completed yet User 2 will see that the item is out of stock.
Now imagine for some reason T1 fails before committing. Now User 2 thought the item was out stock although User 1 could not buy the item.
2. Non-Repeatable Reads
Transaction T1 reads a row twice and gets different results. This might be because another transaction changed a value in the row or deleted the row.
3. Phantom Reads
Transaction 1 executes the same read statement and see rows were not shown with the first read. This might be because another transaction inserted new rows that match T1’s read criteria.
For our hypothetical example, we could avoid the issues shown above with a better design. There are also different isolation levels that brings different levels of consistency. Choosing an appropriate isolation level for our business is a critical decision.
Understanding Locks
Before moving on with transaction isolation levels, let’s understand what different locks mean.
Locking is all about achieving the promised level of consistency. To do so, each isolation level uses different locking methods based on their promise.
Shared Lock (S Lock)
The transaction that holds the lock can read the row.
If a transaction T1 holds a shared lock on row R:
-Second transaction T2 can acquire an S lock on the row R. They “share” the lock and both can read the row at the same time.
-Second transaction T2 cannot acquire an X lock on the row R. T1 does not share the lock and prevents T2 from modifying the row R.
Exclusive Lock (X Lock)
The transaction that holds the lock can update or delete the row.
If a transaction T1 holds a exclusive lock on row R:
-Second transaction T2 cannot acquire an S or an X lock on the row R. The lock belongs only to T1 until T1 releases it.
Non-Locking Reads
Non-Locking reads are the “SELECT” statements that does not put a lock on the rows. These are plain “SELECT” statements in the form of “SELECT … FROM …”. They do not guarantee consistency.
Locking Reads
Locking reads are the “SELECT” statements that puts a lock on the rows to prevent others from changing them.
Record Lock
A record lock is a lock only on the index record. This lock prevents others from modifying that record.
Gap Lock
Gap Locks are set on a gap between index records. It is to prevent other transactions from inserting new rows into the locked gap.
Gap locks are a part of the next-key lock. InnoDB uses locks the related gaps to make sure we do not encounter phantom rows in the range we are working on.
Next-Key Lock
Next-key locks are combination of record locks and gap-locks. A record lock on the record and a gap lock is set in the range we do not want to be effected by another transaction. This might be the gap before and/or after the record we are dealing with.
Transaction Isolation Levels
Transaction isolation levels are like presets with different levels of consistency-performance trade-offs.
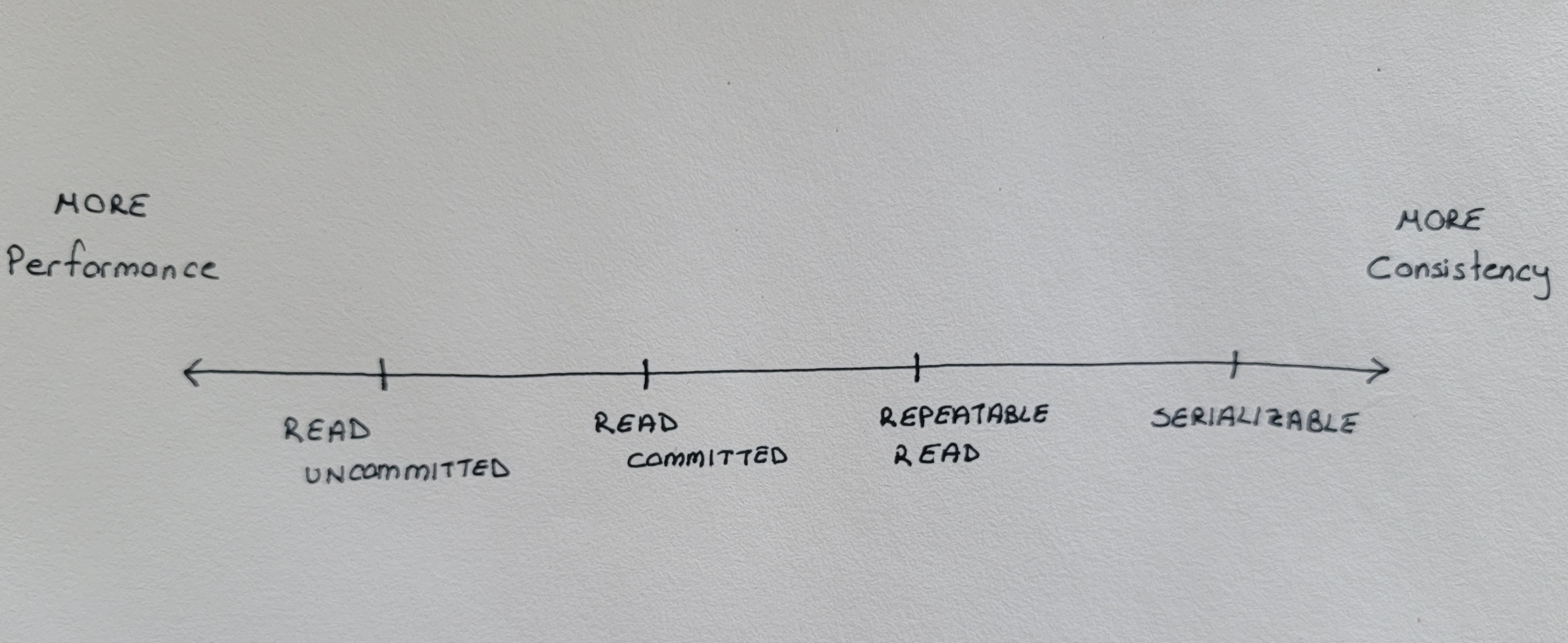
Different transaction isolation levels solve different problems.
Read Uncommitted
At this level, transaction isolation is at the lowest - they are not isolated and no locks are set when at this level. Each transaction will read the latest change by other transactions. Even though those changes are not committed yet. This may result in dirty reads.
Read Committed
At this level, transactions only read only the committed changes by other transactions. This level only prevents dirty reads.
For “SELECT … FOR UPDATE”, “SELECT … FOR SHARE”, “UPDATE” and “DELETE” statements InnoDB locks the index records. This is to prevent other transactions from modifying those rows.
Repeatable Read
This is the default transaction isolation level for InnoDB.
At this level, the reads inside a transaction are consistent. The transaction takes a snapshot of the current state with the first read and uses that through out the transaction. This ensures that all reads can be repeated in the same transaction, thus the name Repeatable-Read. This level prevents dirty reads and non-repeatable reads.
At this level, InnoDB uses next-key locks for searches and index scans. Next-key locks prevents Phantom Reads. It is important to note that this level guarantees no phantom rows only for “Read” operations. An “UPDATE” to all the records in the table would take effect on “all the committed rows”. This includes the ones from other transactions - those are phantom rows. This means Phantom Rows can still appear at this level.
Serializable
At this level, transactions are completely isolated from each other. This prevents dirty reads, non-repeatable reads and phantom reads.
As we can see each transaction isolation levels solve different problems. The way we achieve isolation is through the use of different locking mechanisms.
Conclusion
When understanding locks in databases we need to keep in mind that the purpose is to provide a certain level of consistency. And as the saying goes, there is no such thing as a free lunch. To get more consistency we are going to need to add more locks, more locks mean more overhead, thus loss in performance. To be able to choose an appropriate solution, we must understand the needs of our system.